
Permissionless
When AI agents work perfectly, the world will change in more ways than we might be paying attention to.

If you squint hard enough at Silicon Valley right now, you can see the new feudal architecture taking shape.
At the top of the food chain sit the Cloudalists - a.k.a the “Magnificent Seven”. These aren’t just companies; they are landed gentry. They own the digital soil (the servers), the roads (the networks), and the town squares (the platforms). They are currently busy rewiring the physics of our reality: overhauling national power grids for their data centres; reforming labour markets; rewriting surveillance laws; manipulating the old landed gentry and lobbying anyone with a pulse to clear the runway for their absolute reign.
Down in the mud, you have the rest of us.
The Cloud Serfs: That’s you and me, scrolling for free, paying with our attention and data.
The Vassal Capitalists: The merchants and media companies who create the actual value but have to pay extortionate “rent” just to set up a stall in the Cloudalist’s fiefdom.
But there is a glitch in the matrix. A new creature has jumped the perimeter moat (certain of its clan were even “aqua-hired” to use a phrase of the Silicon Duchy for their fortitude against the current) and is now climbing the castle walls.
Let’s call this creature “Cerplexity GPFree”.
Cerplexity GPFree (a jagged fusion of Perplexity, ChatGPT, and the coming wave of autonomous agents) doesn’t care about the old feudal contracts. It has no interest in serving you ten blue links of SEO-optimised garbage. It wants to shortcut the Cloudalists entirely.
It is whispering to the serfs: “Psst. You want the answer? I’ll just give it to you”. (There are rumours swirling that the exchange might not be as virtuous as it sounds.)
It is a coup d’état in code.
I recently overheard some “beef” is brewing between the Cloudalists and this Cerplexity GPFree thing. I don’t fully understand the technicals, but I know the smell of ozone and fear.
Here is my pontification on the significance of the battles to come....
Hey friends 👋
Forgive my playful primer 😊. (An author’s privilege means it makes the final edit.)
But in “actual” recent news Amazon sent Perplexity a cease-and-desist letter last month. Not because Perplexity’s AI shopping agent was broken or behaving maliciously - but because it was working exactly as it had been conceived and designed.
Perplexity’s “Comet“ agent helps users (amongst other things) navigate and take actions on websites on their behalf. Amazon’s objection? The agent wasn’t identifying itself as a bot. Perplexity’s response was fascinating: since the agent acts on behalf of a human user, it automatically inherits that user’s permissions. The agent is the user, digitally speaking.
Amazon disagreed. And buried in this corporate spat is a question that is probably provoking anyone thinking about AI, privacy, or the future of digital business:
when you authorise an AI agent to act on your behalf, what might be the implications beyond your “in-the-moment” objective?
Writing “used to be” my forcing function to develop clarity..
I’ve been circling this topic all year. Back in January, I wrote about the battle for digital attention and intention - how OpenAI launching Operator through its own browser signalled a fight for who controls the rails that agents operate on. The question then was probably more commercially framed: how quickly would we need to optimise for both human and agentic discovery (SEO vs AOO), and how might our relationship with customers (and the interface that facilitates the exchange) evolve..
In October, I explored a different threat: prompt injection (a fundamental weakness to the architecture of large language models), showcasing examples of where malicious actors hide instructions in PDFs or websites that hijack AI into doing things you never authorised. That’s the adversarial risk - agents being tricked (remarkably easily) into leaking your data.
This piece is about something I probably find more interesting and disruptive: what happens when agents work exactly as intended.
A shadow intelligence capture
If it’s not already, it will likely become commonplace to ask an AI agent to book you a restaurant, coordinate with three friends, and add it to your calendar. To do this, the agent will likely require access to your browser, your contacts, your messages, your calendar, and probably your location.
Now multiply that by millions of users. The company operating that agent isn’t just helping individuals - they’re accumulating an intelligence layer across everyone’s behaviour, preferences, relationships, and patterns.
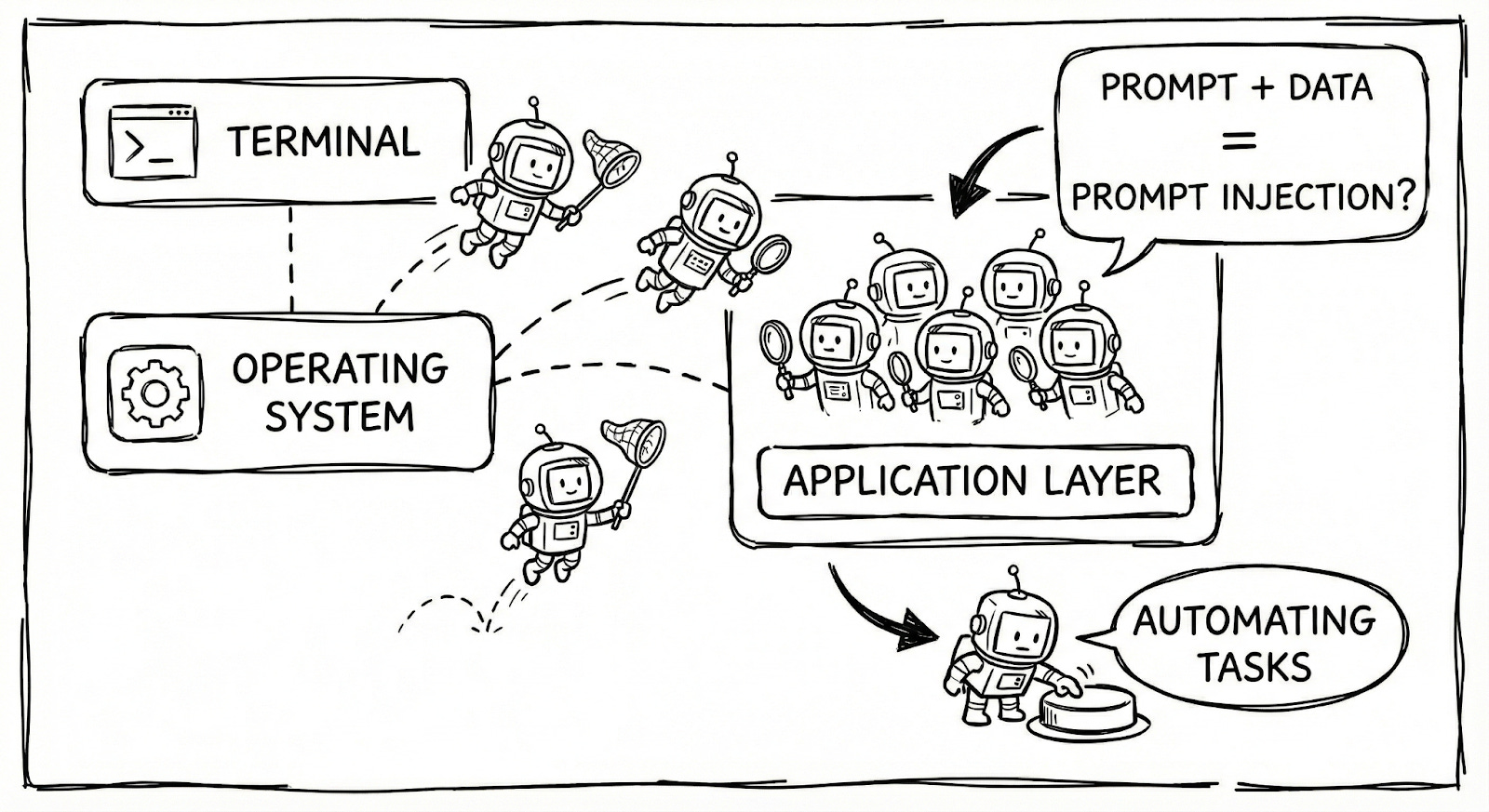
Traditional ad tracking required websites to install tracking pixels - a collaborative act. AI agents don’t need collaboration. They see whatever you can see, wherever you can see it (agnostic of any individual application’s security or OS permission layer).
🗣️ Signal President Meredith Whittaker uses a vivid metaphor: AI agents threaten to break “the blood-brain barrier between the application layer and the OS layer.“
Right now the apps we use exist in relative isolation (built on top of operating systems that act as quasi regulators for how applications are developed and how ultimately digital commerce is facilitated).
Signal can’t see your Spotify. Your banking app can’t read your emails. Privacy and security are enforced at the application level - each app is its own little fortress.
AI agents dissolve those walls. To be useful, they need to operate across your apps, orchestrating actions that span your entire digital life. But that means:
Your end-to-end encrypted messages? Visible to the agent (and processed on one more cloud server, and not just your device)
Your private permissioned platform data? Your pricing strategy or product features? Each is accessible if the agent can see your (or your customer’s) screen OR either of you are operating in its browser.
This is probably why Amazon actually cares
Back to the Perplexity dispute. Amazon’s concern probably isn’t really about robots.txt etiquette. It’s probably about something more fundamental.
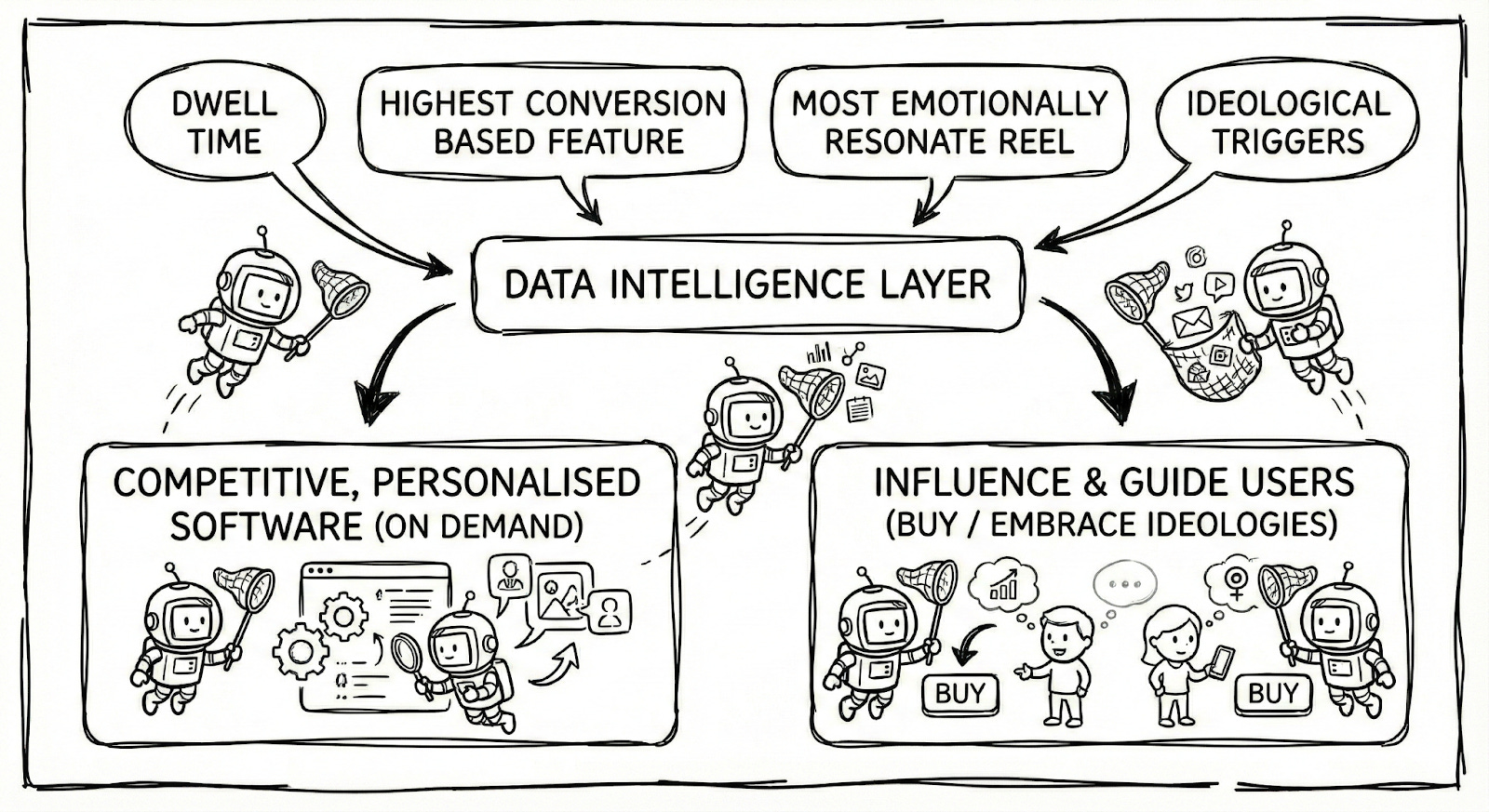
Amazon has spent decades building a personalisation engine - a data moat based on what you browse, buy, abandon at checkout, and return. That intelligence is proprietary and enormously valuable.
An AI shopping agent that can navigate Amazon using your credentials doesn’t just help you shop. It observes Amazon’s entire user experience through millions of eyes. It sees which products get recommended, how prices change, what the buy box algorithm favours. It probably starts to capture intelligence that Amazon has never shared with anyone. Amazon likely perceives that if third party agents (that achieve a certain scale and proliferation) can freely harvest data from platforms using borrowed human credentials, the value of proprietary data (and the practices built off them) starts to erode.
Why build a personalisation engine if someone else can just... watch it work?
At this stage, I should call out that I’m not here to evoke empathy for Amazon, but you’ll appreciate that they are just a convenient (Cloudalist impacted) example of the disruption that might be to come…
Is there a “Market Effect” question
Dana Rao recently offered a sharp observation on AI and copyright: TL;DR the through-line in court analyses is whether AI creates a “market effect” that harms (through competition) the original work.
What strikes me is how this “market effect” lens might apply beyond training data to the operational data AI agents observe. When an agent watches you navigate Amazon, it’s not just helping you shop - it’s creating intelligence about Amazon’s recommendation algorithms, pricing strategies, and user experience patterns. Multiply that by millions of users, and you have something that could meaningfully affect Amazon’s market position.
Is that a “market effect”? I’m not sure there are legal frameworks that cover this (I’d love to know and hear from you if you have more intelligence and ideas than me here)?
Most of us have agreed to terms allowing platforms to use our company’s behavioural data for product improvement. But that language predates agents that can learn self-recursively and act on what they observe in near real-time. Is it time to ask whether those old permissions still mean what we thought they meant?
What this might mean for us (I don’t know!)
For those of us working at the intersection of law, technology, copyright, privacy and policy (advising businesses or governments on the same), this raises some uncomfortable questions:
On data protection: How do you advise clients on data security when an employee’s AI agent can see - and transmit to a third party - anything that employee can access? The “lethal trifecta” (coined by Simon Willison) which I described in October (private data + untrusted content + external communication) is the default architecture of most useful agents. Cloudera’s research found 53% of organisations identify data privacy as their primary obstacle to AI agent adoption - and they’re right to be cautious.
On competitive intelligence: If your employees (or even, customers) use AI agents that report back to OpenAI, Anthropic, Google, or Perplexity, what are you inadvertently revealing about your business? Your pricing, your product, internal processes, your communications?
On terms of service: Perplexity’s argument - that an agent inherits the user’s permissions - is legally untested. If that argument prevails, every terms of service that distinguishes between human users and automated access becomes unenforceable. If it fails, we need new frameworks for what “authorised use” means in an agentic world.
On building products: Are you building for AI agents (optimising for discoverability and integration) or against them (protecting proprietary data)? The answer probably isn’t binary, but it’s a question worth asking explicitly - because the “market effect” of agents may extend well beyond what current legal frameworks contemplate.
No clear answers
I don’t have a neat conclusion here. This isn’t a “five steps to protect yourself” situation - the risks are structural, not just behavioural.
But I do think we’re at an inflection point.
This new battle - over what AI agents are permitted to see, and who benefits from that seeing - might reshape something more fundamental: when you click “allow” or “authenticate” on an AI agent, you’re not just granting access to yourself. You’re potentially lending your credentials to an intelligence operation you don’t control, can’t audit, and may not even understand.
Thank you for reading 🙏
🔮 If you are interested in learning more about the wild, fantastical (and fictional?) fate of the Cloudalists, Serfs,Vassal Capitalists and Cerplexity GPFree please let us know?
We’re contemplating getting creative with a short series early in the new year..